Интернационализация на основе CSS с использованием JavaScript
При написании фронтенд-кода перед разработчиком обычно рано или поздно возникает задача интернационализации. Несмотря на то, что в текущем стандарте представлен ряд новых тегов, простое добавление поддержки разных языков в плагине JavaScript остаётся сложным. Как результат, для каждого нового проекта приходится придумывать решение с ноля или приспосабливать различные API из других плагинов, которыми вы пользуетесь.
В этой статье я опишу свой подход к решению задачи интернационализации с помощью библиотеки better-dom. С момента написания своей последней статьи на эту тему, «Пишем лучшую JavaScript-библиотеку для DOM», я пересмотрел свою концепцию и исправил некоторые моменты, на которые мне указали в отзывах.
Изначально, решение должно было базироваться на наборе API интернационализации для плагинов, расширений и т.д. Оно не слишком сильно привязано к библиотеке better-dom, потому могло быть адаптировано под любую из существующих библиотек JavaScript.
Типичное решение проблемы
В JavaScript есть множество API для изменения языка. Большинство из них содержит три главные функции:
- Первая функция регистрирует локализированную строку, прописывая ключ и язык.
- Вторая привязывает локализированную строку для конкретного элемента.
- Третья используется для изменения текущего языка.
Давайте рассмотрим пример на основе плагина Validator из библиотеки
jQuery Tools. Плагин поддерживает локализацию ошибок валидации через
JavaScript. Сообщения об ошибках по умолчанию хранятся в объекте
$.tools.validator.messages.
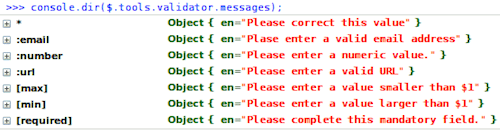
Сообщения об ошибках по умолчанию хранятся в объекте
$.tools.validator.messages.
В качестве ключей плагин использует CSS-селекторы (с целью упрощения кода). Если
вы хотите отобразить сообщение об ошибке на другом языке, следует использовать
метод $.tools.validator.localize:
$.tools.validator.localize("fi", {
":email" : "Virheellinen sähköpostiosoite",
":number" : "Arvon on oltava numeerinen",
"[max]" : "Arvon on oltava pienempi, kuin $1",
"[min]" : "Arvon on oltava suurempi, kuin $1",
"[required]" : "Kentän arvo on annettava"
});
Этот метод добавляет локализацию на финском языке. Объект
$.tools.validator.messages выглядит так:
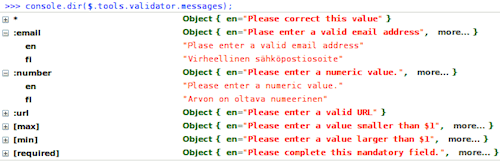
Объект $.tools.validator.messages, наполненный для локализации на финском
языке.
Теперь когда вы хотите использовать в форме финскую локализацию, вам нужно
изменить язык по умолчанию (английский) через параметр конфигурации lang:
$("#myForm").validator({lang: "fi"});
Плагин служит для реализации типичного решения, которое нам доступно на сегодня. Рассмотрев подходы, подобные этому, я нашёл несколько общих недостатков:
- Громоздкость. Если язык текущей страницы отличается от языка, используемого плагином по умолчанию (обычно английского), необходимо добавление вызова функции JavaScript.
- Неэффективность. Для динамического изменения языка, нужно вызвать
определённую функцию и затем обновить
innerHTMLв DOM каждого соответствующего элемента в зависимости от нового языка. - Сложности в обслуживании. У каждого плагина есть свой собственный набор API.
Первый недостаток является наиболее критичным. Если ваш проект состоит из большого количества компонентов, переключение языка при первой загрузке страницы для каждого плагина будет сплошным мучением. Если для извлечения данных в проекте используются вызовы AJAX, те же шаги нужно будет предпринять также и для будущего контента. Давайте попытаемся избавиться от этих недостатков. Во первых, нам нужно разобраться с технической стороной.
Псевдокласс :lang
Помните в CSS2 был такой псевдокласс как :lang? Он редко используется, но
когда я впервые прочитал о нём в спецификации, мне стало интересно, чего
хотели с его помощью добиться авторы спецификации:
Если в тексте документа указано как определить язык элемента, становится возможным написание селекторов CSS, которые воздействуют на элемент в зависимости от его языка.
Типичным примером, который приводится в спецификации, являются знаки препинания
в цитатах. В разных языках они отличаются. Для изменения используемых символов
для элемента <q> (который обозначает краткую цитату, обычно заключённую в
кавычки), можно использовать псевдокласс :lang:
:lang(fr) > q { quotes: '« ' ' »' }
:lang(de) > q { quotes: '»' '«' '\2039' '\203A' }
Существенной разницей между псевдоклассом :lang и простым селектором по
атрибуту вроде [lang=fr], является то, что последний работает только для тех
элементов, у которых указан атрибут lang. Следовательно, псевдокласс :lang
более надежен, чем вариант с атрибутом, так как он работает должным образом даже
когда атрибут :lang для элемента не прописан.
Пример выше показывает, как можно с помощью CSS изменить представление контента в зависимости от текущего языка. Это важно, поскольку даёт нам возможность использовать в CSS логику для изменения языка.
Пример с кавычками неплох, но он охватывает очень ограниченное количество задач и в общем случае его использовать не получится — в разных языках строки, которые нужно локализировать, слишком сильно отличаются. Нам нужен трюк, который позволит полностью изменять содержимое элемента.
Изменение содержимого элемента с помощью CSS
В браузерах, поддерживающих спецификацию CSS2, были представлены псевдо-элементы, которые вместо того, чтобы описывать определённое состояние как псевдоклассы, позволяют стилизовать определённые части документа.
Обратите внимание на то, что в Internet Explorer 8 существует проблема в реализации спецификации, он не поддерживает синтаксис двойного двоеточия при определении псевдоэлементов. В Internet Explorer 9 эта ошибка исправлена, однако если вам нужна поддержка 8 версии, для всех псевдоэлементов используйте только синтаксис с одним двоеточием.
::before и ::after являются настоящими жемчужинами, так как позволяют
добавлять дополнительный контент перед или после innerHTML элемента. Возможно,
в них и нет ничего замысловатого, однако можно привести уйму практических
примеров, когда они позволяют решить задачу не захламляя код.
Начнём с основ. И ::before, и ::after вводят новое свойство CSS, content.
Это свойство определяет, какой контент нужно добавить перед или после innerHTML
элемента. Значением атрибута content может быть любое из следующего:
- текстовая строка (но не строка с HTML),
- изображение,
- счётчик,
- значение атрибута.
Нас больше всего интересует добавление текстовой строки. Возьмем такой CSS:
#hello::before {
content: "Hello ";
}
Если элемент с идентификатором hello содержит строку world, браузер
отобразит Hello world.
<p id="hello">world</p>
Можно переписать CSS используя функцию attr:
#hello::before {
content: attr(id) " ";
}
Тогда на месте элемента будет отображаться hello world в нижнем регистре, так
как у атрибута id задано значение строки в нижнем регистре.
Теперь представьте, что у элемента hello нет внутреннего наполнения. Тогда с
помощью CSS его представление можно менять полностью. Это очень удобно в
сочетании с псевдоклассом :lang:
#hello::before {
content: "Hello";
}
#hello:lang(de)::before {
content: "Hallo";
}
#hello:lang(ru)::before {
content: "Привет";
}
Теперь наш элемент hello будет меняться в зависимости от языка текущей
страницы — для изменения его представления не нужно вызывать никакие функции.
Локализация осуществляется на основе значения атрибута lang для элемента
<html> и нескольких дополнительных CSS-правил. Это именно то, что я называю
интернационализацией с помощью CSS.
Интернационализация с помощью CSS: улучшенная версия!
С момента изложения исходной идеи я получил несколько негативных отзывов с
жалобами на то, что использование таких правил значительно увеличит объем CSS.
Поскольку изначально я собирался использовать его для маленьких плагинов
JavaScript, я даже подумать не мог, что этот подход будет использоваться для
целых страниц. Однако согласно философии CSS, он должен содержать
презентационную логику, а я попробовал использовать его для хранения различных
мультиязычных строк, которые вообще-то должны быть содержимым веб-страницы.
Вышло не очень.
После некоторых размышлений я разработал улучшенную версию, которая решает эту
проблему. Вместо того чтобы помещать текстовые строки в CSS, я использую
функцию attr для чтения языкового атрибута data-i18n-*, который содержит
локализованную строку. Это ограничивает количество CSS-правил, которые можно
добавить, до одного правила для каждого языка.
Перепишем пример локализации элемента hello, применив этот улучшенный метод. В
этот раз добавим нашей веб-странице немного глобального CSS для поддержки
немецкого и русского языка в добавок к английскому:
/* английский (язык по умолчанию)*/
[data-i18n]::before {
content: attr(data-i18n);
}
/* немецкий */
[data-i18n-de]:lang(de)::before {
content: attr(data-i18n-de);
}
/* русский */
[data-i18n-ru]:lang(ru)::before {
content: attr(data-i18n-ru);
}
Обратите внимание, что код выше не содержит никаких неизменимых строк: CSS-правила являются универсальными.
Теперь вместо того, чтобы помещать в CSS локализованные текстовые строки,
добавим несколько языковых атрибутов data-* с соответствующими значениями. Наш
элемент hello должен выглядеть так и отображать разное содержимое в
зависимости от языка текущей страницы:
<p id="hello" data-i18n="Hello" data-i18n-de="Hallo" data-i18n-ru="Привет"></p>
Вот и всё! Теперь у нас минимум дополнительного CSS, который описывает только глобальную логику изменения представления элемента в зависимости от текущего языка и наши локализованные строки находятся целиком в HTML.
Разработка высокоуровневого API
В better-dom для поддержки интернационализации с помощью CSS предусмотрены две функции:
$Element.prototype.i18n и DOM.importStrings. Первая функция изменяет
локализованную строку для конкретного элемента. Чтобы не усложнять, я всегда
использую строки на английском языке в качестве ключей и значений по умолчанию.
Это делает JavaScript более простым для чтения и понимания. Например:
myelement.i18n("Hello");
Это устанавливает локализованную строку Hello в качестве внутреннего контента
myelement, при чём myelement является представителем класса $Element,
который приходится обёрткой для встроенного элемента DOM в библиотеке better-dom.
Строчка кода, приведённая выше, выполняет несколько скрытых действий:
- Определяет текущий набор зарегистрированных языков.
- Для каждого языка она проверяет строку с ключом
Helloво внутреннем хранилище зарегистрированных локализаций и использует её значение для выбора подходящего атрибутаdata-i18n-*для элемента. - Подчищает
innerHTMLэлемента для предотвращения отображения странных результатов.
Исходный код $Element.prototype.i18n можно увидеть на GitHub. Целью
метода i18n является обновление языковых атрибутов data-*. Например:
<p id="hello"></p>
Если вы зарегистрировали все локализованные строки для немецкого и русского языка, после вызова этот пустой элемент станет таким:
<p id="hello" data-i18n="Hello" data-i18n-de="Hallo" data-i18n-ru="Привет"></p>
Кроме того, метод i18n поддерживает необязательный второй параметр,
ассоциативный массив переменных:
// Используйте {varName} в шаблоне строки для определения
// разных частей локализованной строки.
myelement.i18n("Hello {user}", {user: username});
// Используйте массив и {varNumber} для определения числового
// множества переменных.
myelement.i18n("Hello {0}", [username]);
Чтобы зарегистрировать локализованную строку, передайте три параметра с помощью
статического метода DOM.importStrings:
- язык перевода,
- ключ локализованной строки (обычно это строка на английском языке),
- значение локализованной строки.
Для примера, приведённого выше, перед применением метода i18n, нам нужно
совершить следующие вызовы:
DOM.importStrings("de", "Hello {user}", "Hallo {user}");
DOM.importStrings("ru", "Hello {user}", "Привет {user}");
DOM.importStrings("de", "Hello {0}", "Hallo {0}");
DOM.importStrings("ru", "Hello {0}", "Привет {0}")
За кулисами DOM.importStrings проходит несколько шагов. Сначала он проверяет
был ли зарегистрирован язык перевода. Если нет, то он добавляет глобальное
CSS-правило:
[data-i18n-{lang}]:lang({lang})::before {
content: attr(data-i18n-{lang});
}
Затем он сохраняет локализованную строку, пару ключ-значение, во внутреннем
хранилище. Исходный код DOM.importStrings можно посмотреть на GitHub.
С помощью DOM.importStrings можно переопределить существующие строки на
английском. Это может пригодиться, если вам нужно адаптировать строки под свои
потребности, не изменяя исходный код:
DOM.importStrings("en", "Hello {user}", "Hey {user}");
DOM.importStrings("en", "Hello {0}", "Hey {0}");
Как видите, эти вспомогательные средства освобождают нас от необходимости писать шаблонный код и позволяют использовать интернационализацию на основе CSS без затруднений.
Преимущества интернационализации на основе CSS
Давайте пересмотрим список проблем, приведённый в первой части этой статьи.
Является ли этот подход громоздким?
Как уже говорилось, при использовании первой версии решения требовалось добавить
вызов функции JavaScript, если язык текущий язык страницы не являлся языком по
умолчанию (обычно английским), используемым для плагина. Большим преимуществом
локализации на основе CSS является то, что для переключения на язык перевода
используется псевдокласс :lang. Это значит, что для выбора нужной
локализованной строки достаточно прописать соответствующее значение для атрибута
lang элемента <html>.
Таким образом, выполняя локализацию на основе CSS, при загрузке страницы не нужно ничего вызывать, даже если язык страницы отличается от языка по умолчанию. Следовательно, этот подход достаточно компактный.
Является ли он эффективным?
Для динамического изменения языка нам приходилось вызывать определённую функцию,
а затем обновлять innerHTML каждого релевантного элемента в зависимости от
языка. Теперь представление элемента управляется псевдоэлементом ::before.
Чтобы динамически переключиться на другой язык на глобальном уровне, просто
измените атрибут lang элемента <html> (например, используя встроенные API).
Или же для изменения языка в конкретной части кода, просто измените атрибут
lang в конкретном поддереве.
Кроме того, для динамического изменения текущего языка не нужно обновлять
innerHTML всех релевантных элементов. Этим занимается CSS. Итак, теперь наш
код более эффективен.
Прост ли он в обслуживании?
Изначально для каждого плагина нужна была индивидуальная подборка API. Функциональное решение для локализации должно быть частью каждой серьезной библиотеки, которая затрагивает дерево документа. Локализация на основе CSS с самого начала является частью моей работы над better-dom, так как мне пришлось решать эту задачу. Я также добавил её в проект better-form-validation для настройки подсказок при валидации форм. Позже я использовал её в проектах better-dateinput-polyfill и better-prettydate. API для локализации, встроенные в корневую библиотеку позволяют значительно сократить количество стандартного кода и положительно влияет на стабильность, последовательность и, как вы уже наверное догадались, простоту в поддержке.
Ограничения интернационализации на основе CSS
Как насчёт недостатков интернационализации на основе CSS?
JavaScript
Во первых, решение основано на JavaScript. Помещение локализованных строк в
атрибуты data-* на статических веб-страницах — не очень хорошая идея, потому
что, с семантической точки зрения, разметка становится странной. Следовательно, я
бы советовал использовать набор JavaScript API (как описано выше) чтобы сделать
концепцию пригодной к использованию.
Убедитесь, что используете её в тех частях страниц, которые не являются жизненно важными для SEO, так как ботам поисковиков будет довольно трудно правильно проиндексировать полученную разметку. Помните, что это решение изначально было разработано как набор API для локализации под плагины и расширения JavaScript.
Псевдоэлементы
Некоторые ограничения также обуславливаются использованием псевдоэлементов
::before и ::after:
- Свойство
contentне работает для пустых элементов (то есть, тех, которые не могут содержать текст) или некоторых элементов форм, в том числе<input>и<select>. - Свойство
contentне может отобразить HTML-тэги. - Значения атрибутов элементов HTML локализировать нельзя (такие как
placeholderиtitle).
Что касается первого ограничения, отсутствие поддержки пустых элементов не такая
уж большая проблема. Такие элементы не содержат никакого контента, так что и
локализировать в них нечего. Однако проблема проявилась во всей красе, когда я
работал с элементом <input> в better-dateinput-polyfill. Чтобы как-то это
решить я спрятал исходный элемент и добавил дополнительный <span> в
качестве обёртки, содержащей локализованную строку, которую мне нужно было
отобразить. Не очень изящно, зато сработало.
Второго и третьего ограничения пока лучше избегать. У меня есть парочка идей как с ними можно справиться, однако у меня нет реальных примеров, где их можно применить. Изящное решение, конечно же, приветствуется.
Решение проблем доступности
Обновлено (24.06.2014): В комментариях к статье несколько читателей отметили,
что использование псевдоэлементов для отображения локализованных строк ведёт к
серьезным проблемам с доступностью. Первая проблема состоит в том, что контент,
сгенерированный через ::before и ::after, не может быть выделен с помощью
курсора мыши. Вторая — в том, что такой контент не распознаётся скринридерами.
Следовательно, я улучшил концепцию с учётом этих моментов и предлагаю
посмотреть демо. Оно пока не включено в better-dom API, но будет
добавлено в следующей версии.
Главная разница в том, что вместо псевдоэлементов контент отображается в
элементах <span>, ориентированных на конкретный язык. Отобразить несколько
таких элементов одновременно нельзя, так как <span>-ы для других языков
прячутся с помощью правила display:none. Скринридеры такие спрятанные элементы
игнорируют, что нам и нужно.
Использование внутренних <span> вместо псевдоэлементов также решает проблему
с выделением курсором и отсутствием поддержки HTML-тэгов внутри локализованных
строк. Тем не менее, проблемы с элементами форм и локализацией значений
атрибутов остаются актуальными.
Заключение
Надеюсь в скором времени в спецификацию будет добавлено простое решение проблемы интернационализации в JavaScript. До того времени нам, фронтенд-разработчикам, придётся заново придумывать колесо или же приспосабливать колёса друг друга под свои потребности.
В процессе разработки этого подхода к интернационализации на основе CSS меня вдохновили идеи, которые содержатся в самой спецификации CSS2. Возможно, её авторы также подумывали о таком подходе. Кто знает?
После нескольких прогонов решение кристаллизировалось. Конечно же, некоторые ограничения всё ещё есть. Однако его преимущества, такие как негромоздкость, например, помогают сделать код существенно чище и проще в обслуживании. Надеюсь, эта статья дала вам представление о том, через что я прошёл чтобы этого достичь.
Обмен мнениями в репозитории библиотеки better-dom на GitHub или же в комментариях ниже приветствуется.


{kind=link}
{kind=link}