Искусство Node
Введение в Node.js
Статья предназначена тем, кто хотя бы немного знаком с:
- языками программирования, например, JavaScript, Ruby, Python, Perl, и т.д. Если вы пока не являетесь программистом, наверное, проще будет начать с чтения «JavaScript для котиков».
- Git и GitHub. Это инструменты для совместной работы с открытым кодом, которые широко используются членами сообщества Node.js для обмена модулями. Вам достаточно знать азы. Вот три отличных самоучителя для начинающих: 1, 2, 3
Написание этой короткой книги всё еще в процессе. Если она вам нравится, пожалуйста, пожертвуйте доллар через gittip чтобы я мог оправдать время, которое займет написание продолжения.
Содержание
- Учим Node.js в интерактивном режиме
- Философия Node.js
- Базовые модули
- Колбеки
- События
- Потоки
- Модули и пакетный менеджер Node.js
- Разработка на стороне клиента с использованием npm
- Выбираем инструменты правильно
Учим Node.js в интерактивном режиме
Исключительно важно не только прочитать это руководство, но и запустить ваш любимый текстовый редактор и, собственно, попробовать написать пару строчек кода на Node. Я уже не раз замечал для себя, что информация, прочитанная в книге, редко откладывается в голове, а вот изучение кода посредством написания является лучшим подходом к освоению новых концепций программирования.
NodeSchool.io
NodeSchool.io — это подборка интерактивных мастер-классов, бесплатных и с открытым кодом, в которых изложены принципы Node.js и не только.
Мы научим вас Node.js — вводный мастер-класс от NodeSchool.io. Это набор задач по программированию, который поможет вам познакомиться с наиболее распространенными паттернами Node. Он доступен в виде консольной программы.
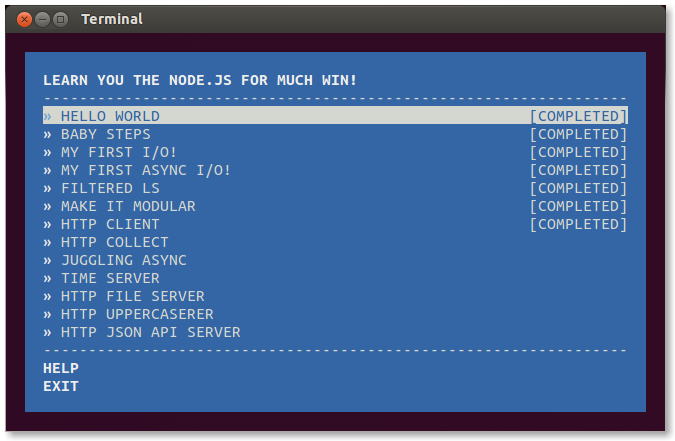
Её можно установить с помощью пакетного менеджера Node:
# install
npm install learnyounode -g
# start the menu
learnyounode
Философия Node
Node.js — это проект с открытым исходным кодом, разработанный, чтобы помочь вам создавать программы на JavaScript, которые могли бы взаимодействовать с сетями, файловыми системами или другими I/O источниками ввода/вывода. Вот и всё! Это простая и стабильная I/O платформа, на основе которой предлагается создавать свои модули.
Какими бывают источники ввода/вывода? Вот схема моего приложения, построенного на Node, которая отображает многообразие источников:
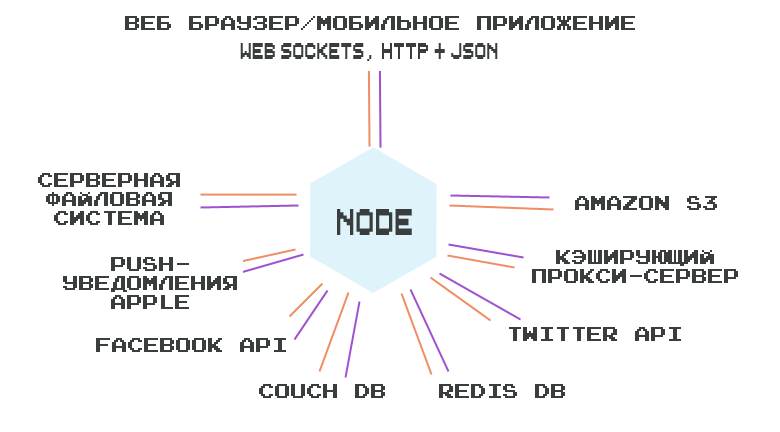
Ничего страшного, если в этой схеме вам понятны не все надписи. Её смысл в том, чтобы показать, что один-единственный процесс Node.js (шестигранник в центре) может служить посредником между различными конечными точками (оранжевые и фиолетовые линии представляют ввод/вывод).
Обычно создание подобных систем подразумевает одно из двух:
- сложный код, но с супербыстрым результатом (как в случае с написанием веб-сервера с нуля на С)
- простой код, однако не слишком быстрый/надежный результат (например, когда кто-нибудь пытается загрузить файл весом 5Гб и сервер падает)
Цель Node.js состоит в достижении золотой середины: относительная простота понимания и использования в сочетании со скоростью работы в большинстве случаев применения.
Node.js не является:
- Веб-фреймворком (вроде Rails или Django, хотя его можно использовать для создания таких вещей)
- Языком программирования (для него используется JavaScript, Node.js не является языком сам по себе)
Node.js — это нечто среднее. Он:
- Создан чтобы быть простым и, следовательно, относительно лёгким для понимания и использования
- Будет полезным для программ, предусматривающих операции ввода/вывода, которые должны быть быстрыми и выдерживать большое количество соединений
На более низком уровне Node.js можно описать как инструмент для написания программ двух типов:
- Сетевых программ, использующих веб-протоколы: HTTP, TCP, UDP, DNS и SSL
- Программ, производящих чтение и запись данных в/из файловых систем или локальных процессов/памяти.
Что следует понимать под «программами, предусматривающими операции ввода/вывода»? Вот некоторые наиболее типичные I/O источники:
- Базы данных (напр. MySQL, PostgreSQL, MongoDB, Redis, CouchDB)
- API (напр. Twitter, Facebook, рush-уведомления Apple)
- Соединения HTTP/WebSocket (от пользователей веб-приложения)
- Файлы (редактор изображений и видео, интернет-радио)
Node.js выполняет операции ввода/вывода асинхронно, что позволяет ему проводить большое количество операций одновременно. Предположим, вы зашли в заведение быстрого питания и заказали чизбургер, вы сделали свой заказ и околачиваетесь поблизости пока его приготовят. В то же время персонал может принимать заказы и готовить чизбургеры для других клиентов. Представьте, что было бы, если бы вы остались ждать свой чизбургер у кассы, не давая остальным посетителям в очереди сделать свой заказ до тех пор, пока ваш чизбургер не будет готов! Это называется блокирующим вводом-выводом, так как все операции ввода/вывода (приготовление чизбургеров) выполняются поочередно, в один момент одна операция. Node, напротив, является неблокирующим, то есть может готовить много чизбургеров одновременно.
Вот несколько занимательных вещей, которые можно легко сделать на Node, благодаря её неблокирующей сущности:
- Управление летающими квадрокоптерами
- Написание IRC-ботов
- Создание двуногих роботов, способных ходить
Базовые модули
Прежде всего я советовал бы вам установить Node.js на ваш компьютер. Самый простой
способ это сделать — зайти на nodejs.org и нажать Install.
У Node.js есть небольшая базовая группа модулей (их принято называть «ядро Node»),
представленных как открытые API, на основе которых следует писать программы. Для
работы с файловыми системами существует модуль fs, для сетей используются
такие модули как net (TCP), http и dgram (UDP).
В дополнение к fs и сетевым модулям, ядро Node.js содержит ряд других базовых
модулей. Есть модуль для асинхронной обработки DNS-запросов под названием dns,
модуль os для получения сведений об ОС, например, о расположении tmpdir,
модуль buffer для распределения бинарных участков памяти, несколько модулей
для анализа ссылок и путей (url, querystring, path) и т.д. Большинство
модулей, составляющих ядро, предназначены для обеспечения главного
предназначения Node: создания быстрых программ, взаимодействующих
с файловыми системами или сетями.
Node.js выполняет операции ввода/вывода с помощью колбеков, событий, потоков и модулей. Если вы разберётесь с тем, как работают эти четыре компонента, вы сможете взять любой модуль из ядра Node.js и более-менее чётко понять как с ним взаимодействовать.
Колбеки
Если вы хотите понять как использовать Node, то нужно прежде всего разобраться с этой темой. Колбеки в Node.js используются практически везде. Они не были придуманы для Node, и являются всего лишь частью языка JavaScript.
Колбеки — это функции, которые выполняются асинхронно, или же в отложенный момент времени. Вместо того, чтобы методично считывать код сверху вниз, асинхронные программы могут выполнять разные функции в разное время, исходя из порядка и скорости выполнения предыдущих функций, вроде http-запросов или считывания файловой системы.
Иногда может быть сложно увидеть разницу, так как является ли функция асинхронной или нет, по большей части зависит от контекста. Вот простой пример синхронной функции, т.е. код можно читать сверху вниз как книгу:
var myNumber = 1;
function addOne() { myNumber++ } // определение функции
addOne(); // выполнение функции
console.log(myNumber); // в консоль выводится 2
Здесь сначала определяется функция, а затем в следующей строке происходит её вызов, без каких-либо отсрочек. Когда происходит вызов функции, она немедленно прибавляет 1 к переменной, так что можно рассчитывать, что после вызова функции значение переменной должно быть равно 2. Это то, чего мы ожидаем от синхронного кода — он последовательно выполняется сверху вниз.
Однако в Node, в большинстве случаев, используется асинхронный код. Попробуем
считать число из файла под названием number.txt, используя Node:
var fs = require('fs'); // require является специальной функцией предусмотренной в Node
var myNumber = undefined; // мы пока не знаем значение переменной, так как оно хранится в файле
function addOne() {
fs.readFile('number.txt', function doneReading(err, fileContents) {
myNumber = parseInt(fileContents);
myNumber++;
})
}
addOne();
console.log(myNumber); // в консоль выводится undefined — эта строчка запускается перед выполнением readFile
Почему при выводе результата в консоль мы видим undefined? В этом
коде мы используем метод fs.readFile, который является асинхронным. Обычно все
взаимодействия с жёстким диском или сетью являются асинхронными. Если требуется
всего лишь получение доступа к памяти или выполнение каких-либо действий с
процессором, можно использовать синхронный подход. Причиной этому является то,
что операции ввода/вывода ооооочень и оооочень меееедленные. По приблизительным
оценкам, взаимодействие с жёстким диском примерно в 100,000 медленнее, чем
взаимодействие с памятью (напр. с оперативной памятью).
При запуске этой программы все функции объявляются немедленно, но не все
выполняются сразу. Это основополагающая вещь для понимания асинхронного
программирования. Когда происходит вызов addOne, она вызывает readFile и
переходит дальше к тому, что ещё может быть выполнено. Если выполнять нечего,
Node.js либо ждёт окончания текущих операций с файловыми системами/сетями или же
прекращает работу и выходит в командную строку.
Когда readFile заканчивает чтение файла (это может продолжаться от
миллисекунды до нескольких секунд или минут, в зависимости от скорости жесткого
диска), он запускает функцию doneReading и передает ей ошибку (если она есть)
и содержимое файла.
Выше мы получили undefined потому, что нигде в коде не прописано, что команда
console.log должна подождать с выводом переменной до завершения работы
команды readFile.
Если вы хотите, чтобы определённый код выполнялся снова и снова, или же в какой-то отложенный момент, первым делом следует поместить его в функцию. Затем эту функцию можно будет вызвать в любое время, когда вы захотите этот код выполнить. Удобнее давать функциям осмысленные названия, говорящие об их предназначении.
Колбеки — это функции, которые могут быть выполнены позже. Ключом к пониманию колбеков является осознание того, что они используются, когда время окончания какой-либо асинхронной операции неизвестно, однако известно место её окончания — последняя строчка асинхронной функции! Порядок сверху-вниз, в котором объявлены функции, не играет особой роли, в отличие от их логической/иерархичной вложенности. Сначала вы разбиваете код на функции, а затем используете колбеки для объявления, что запуск одной функции зависит от окончания другой.
Метод fs.readFile, предлагаемый в Node, является асинхронным, и
иногда его выполнение затягивается на длительное время. Вот что он делает:
он обращается к операционной системе, которая, в свою очередь, обращается к
файловой системе, которая живёт на жёстком диске, вращающемся со скоростью выше
или ниже тысячи оборотов в минуту. Затем с помощью лазера считываются данные
и отсылаются назад в программу тем же путём. Вы передаёте readFile колбек,
который он вызовет после получения данных из файловой системы. Он помещает
полученные данные в javascript-переменную и вызывает колбек с этой переменной
в качестве аргумента. В этом случае переменная носит название fileContents,
так как в неё помещено содержимое прочитанного файла.
Вспомните пример с рестораном, приведённый в начале этого руководства. В большинстве таких заведений вы получаете номерок, который нужно положить на ваш столик, пока вы ожидаете свой заказ. Это очень напоминает колбек. Они говорят серверу что следует сделать когда ваш чизбургер будет готов.
Давайте поместим нашу команду console.log в функцию и добавим её в код в
качестве колбека.
var fs = require('fs');
var myNumber = undefined;
function addOne(callback) {
fs.readFile('number.txt', function doneReading(err, fileContents) {
myNumber = parseInt(fileContents);
myNumber++;
callback();
});
}
function logMyNumber() {
console.log(myNumber);
}
addOne(logMyNumber);
Теперь функции logMyNumber можно передать аргумент, который станет переменной
callback внутри функции addOne. После завершения работы readFile будет
вызвана переменная callback (callback()). Так как вызываться могут только
функции, если попробовать вызвать что-либо кроме функции, мы получим ошибку.
Когда в JavaScript происходит вызов функции, код внутри этой функции немедленно
выполняется. В нашем случае будет выполнена команда вывода в консоль, поскольку
callback по сути является logMyNumber. Помните, что если просто объявить
функцию — она не будет выполнена. Для выполнения функцию нужно вызвать.
Чтобы проанализировать этот пример еще подробней, рассмотрим последовательность событий, которые происходят при выполнении этой программы:
- Сначала код анализируется, а это означает, что если будут обнаружены
синтаксические ошибки — программа работать не будет. На этом этапе
объявляются четыре компонента:
fs,myNumber,addOneиlogMyNumber. Обратите внимание, что происходит только объявление, вызов каких-либо функций пока не производится. - При выполнении последней строчки нашей программы, вызывается
addOne, ей передается функцияlogMyNumberв качествеcallback, которую нам нужно вызвать после завершенияaddOne. Это немедленно запускает асинхронную функциюfs.readFile. Эта часть программы занимает много времени. - Так как больше ему заняться нечем, Node.js пребывает в режиме ожидания пока не
завершится работа
readFile. Если бы какие-нибудь задачи требовали выполнения в этот промежуток времени, Node.js занялся бы их выполнением. readFileзаканчивает работу и вызывает колбекdoneReading, который, в свою очередь, увеличивает число на единицу и немедленно вызывает колбек —logMyNumber, переданный вaddOne.
Наверное, больше всего сбивает с толку то, что с функциями можно обращаться как
с простыми объектами, хранить их в переменных и передавать туда-сюда под разными
именами. Чтобы ваш код мог прочитать кто-нибудь кроме вас, важно давать
переменным простые и наглядные названия. В общем, если вы видите в программе на
Node.js переменную вроде callback или cb, можно предположить, что это колбек.
Возможно, вы слышали термины «событийно-ориентированное программирование» или
«событийный цикл». Они описывают процесс выполнения readFile. Сначала Node
запускает операцию readFile, затем ждёт пока readFile вышлет ему событие,
означающее её завершение. В процессе ожидания Node.js может проверить
состояние других процессов. У Node.js есть список операций, которые были запущены,
но от которых пока не получен ответ, он перебирает их снова и снова, проверяя не
были ли они завершены. После окончания работы они «обрабатываются»,
например, происходит запуск колбека, привязанных к завершению
их работы.
Вот схематическая версия кода, иллюстрирующая приведенный выше пример:
function addOne(thenRunThisFunction) {
waitAMinute(function waitedAMinute() {
thenRunThisFunction();
});
}
addOne(function thisGetsRunAfterAddOneFinishes() {});
Представьте, что у вас есть три асинхронные функции a, b и c. Выполнение
каждой из них занимает минуту, и после завершения каждой происходит запуск
колбека (которому передается первый аргумент). Если вы хотите сказать Node.js
«запусти a, после её завершения выполни b, после завершения b запусти c»
это выглядело бы так:
a(function() {
b(function() {
c();
});
});
При выполнении этого кода, немедленно запустится a, через минуту она закончит
работу и вызовет b, которая закончится еще через минуту и вызовет c, и,
наконец, 3 минуты спустя после начала выполнения Node.js завершит обработку кода,
так как больше задач не останется. Конечно, можно было придумать более
изящные способы записать этот пример, однако смысл состоит в том, что если у вас
есть код, который должен подождать, пока будет завершено выполнение другого
асинхронного кода, то эту зависимость следует выразить, поместив код в колбек.
Структура Node.js требует от разработчика нелинейного мышления. Взгляните на этот список операций:
- чтение файла
- обработка файла
Если бы вам пришлось превратить его в код, у вас получилось бы следующее:
var file = readFile();
processFile(file);
Такой линейный (пошаговый, упорядоченный) код не соответствует тому, как
работает Node. Если начать обработку такого кода, readFile и processFile
выполнялись бы одновременно. Это бессмысленно, так как выполнение readFile
займет много времени. Вместо этого вам нужно указать, что функция processFile
должна быть запущена после завершения readFile. Именно для этого и существуют
колбеки. Благодаря особенностям JavaScript, эту зависимость можно записать
несколькими разными способами:
var fs = require('fs');
fs.readFile('movie.mp4', finishedReading);
function finishedReading(error, movieData) {
if (error) return console.error(error);
// выполнение действий с movieData
}
Однако можно написать и такую структуру кода, и он все так же будет работать:
var fs = require('fs');
function finishedReading(error, movieData) {
if (error) return console.error(error);
// выполнение действий с movieData
}
fs.readFile('movie.mp4', finishedReading);
Или даже так:
var fs = require('fs');
fs.readFile('movie.mp4', function finishedReading(error, movieData) {
if (error) return console.error(error);
// выполнение действий с movieData
});
События
Если вам нужен модуль событий, в Node.js вы можете воспользоваться так называемым «генератором событий», который используется во всех Node.js API, которые что-либо генерируют.
События, более известные как паттерн «наблюдатель» или «издатель/подписчик», являются широко распространённым паттерном в программировании. В то время, как колбеки представляют собой связь «один к одному» между тем, что ожидает колбек и тем, что его вызывает, события представляют собою такую же связь, только между многими API.
Проще всего представить себе принцип работы событий как подписку на нечто. Они позволяют указать «когда Х, сделай Y», тогда как простые колбеки указывают только «сделай Х, затем Y».
Вот несколько типичных случаев использования событий вместо колбеков:
- Чат, в котором вы хотите транслировать сообщения для многих пользователей
- Игровой сервер, которому нужно знать когда новые игроки присоединяются, отсоединяются, двигаются, стреляют и прыгают
- Игровой движок, в котором вы хотите предусмотреть для разработчиков игры
возможность подписываться на события вроде
.on('jump', function() {}) - Веб-сервер низкого уровня, на котором нужно предоставить API для простого
подключения к происходящим событиям вроде
.on('incomingRequest')или.on('serverError')
Если бы мы попробовали написать модуль, подключающийся к серверу чата, используя только колбеки, он бы выглядел так:
var chatClient = require('my-chat-client');
function onConnect() {
// подтверждение подключения в интерфейсе
}
function onConnectionError(error) {
// уведомление пользователя об ошибке
}
function onDisconnect() {
// уведомление пользователя об отключении
}
function onMessage(message) {
// отображение в интерфейсе сообщения из чата
}
chatClient.connect(
'http://mychatserver.com',
onConnect,
onConnectionError,
onDisconnect,
onMessage
);
Как видите, такой способ очень громоздкий, так как функции .connect нужно
передать большое количество функций в определённом порядке. Написание того же с
использованием событий выглядело бы так:
var chatClient = require('my-chat-client').connect();
chatClient.on('connect', function() {
// подтверждение подключения в интерфейсе
});
chatClient.on('connectionError', function() {
// уведомление пользователя об ошибке
});
chatClient.on('disconnect', function() {
// уведомление пользователя об отключении
});
chatClient.on('message', function() {
// отображение в интерфейсе сообщения из чата
});
Это похоже на способ с использованием колбека, однако добавлен метод .on,
который подписывает колбек на событие. Это значит, что вы можете выбирать
на какие события в chatClient нужно подписаться. Также можно подписаться
на одно и то же событие несколько раз, используя разные колбеки:
var chatClient = require('my-chat-client').connect();
chatClient.on('message', logMessage);
chatClient.on('message', storeMessage);
function logMessage(message) {
console.log(message);
}
function storeMessage(message) {
myDatabase.save(message);
}
Потоки
На начальной стадии существования Node.js для файловых систем и сетевых API
использовались разные подходы к обработке потоковых операций ввода/вывода.
Например, для файлов в файловых системах применялись так называемые «файловые
дескрипторы», соответственно, модуль fs был наделён дополнительной логикой,
позволяющей их отслеживать, в то время, как для сетевых модулей такая концепция
не использовалась. Несмотря на подобные незначительные различия в семантике, на
более глубоком уровне считывания и вывода данных у обеих групп кода большая
часть функционального наполнения дублировалась. Команда разработчиков Node
поняла, что не стоит всё усложнять необходимостью изучать два набора
семантических правил для выполнения одинаковых действий, и разработала
новый API под названием Stream — и для сетей, и для файловых систем.
Весь замысел Node.js состоит в упрощении работы с файловыми системами и сетями, поэтому вполне разумно во всех случаях использовать общий паттерн. Хорошая новость состоит в том, что большинство таких паттернов (их всего несколько), на данный момент, уже разработаны и вероятность того, что со временем Node.js сильно изменится, ничтожна.
Для изучения потоков в Node.js есть два отличных ресурса. Один из них — stream-adventure, второй — справочный ресурс под названием «Справочник по потокам».
Справочник по потокам
Справочник по потокам — это руководство, похожее на текущее, которое содержит ссылки на всё, что вам следует знать о потоках.
Модули
Ядро Node.js состоит примерно из двух дюжин модулей, некоторые из них более
низкоуровневые, такие как events и stream, другие — более высокоуровневые,
такие как http и crypto.
Такая структура была придумана специально. Ядро Node.js должно быть небольшим, а модули, его составляющие, должны являться кросс-платформенными инструментами для работы со всеми распространёнными протоколами и форматами ввода/вывода.
Для всего остального существует пакетный менеджер Node. Кто угодно может создать новый модуль Nodе с дополнительными функциональными возможностями и добавить его в npm. На момент написания этой статьи npm насчитывает 34,000 модулей.
Как найти модуль
Представьте, что вам нужно переконвертировать файлы PDF в TXT. Начать лучше
всего с команды npm search pdf:
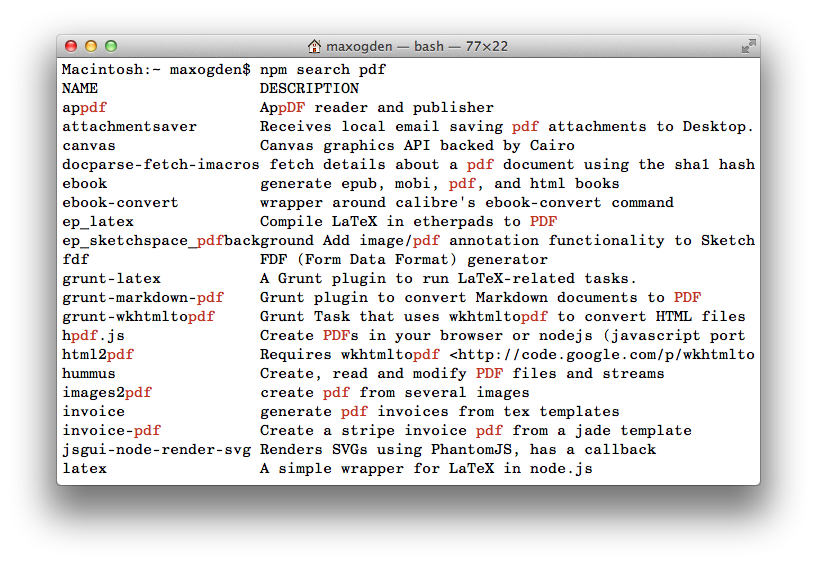
Результатов масса! npm довольно популярен, и в большинстве случаев вы сможете найти несколько потенциальных решений. Если пройтись по модулям и сократить количество результатов (отфильтровав, например, модули для генерации PDF), получим следующие:
- hummus — модуль управления pdf на с++
- mimeograph — api на основе совмещения инструментов (poppler, tesseract, imagemagick и др.)
- pdftotextjs — оболочка для утилиты pdftotext
- pdf-text-extract — ещё одна оболочка для pdftotext
- pdf-extract — оболочка для pdftotext, pdftk, tesseract, ghostscript
- pdfutils — оболочка для библиотеки poppler
- scissors — оболочка для pdftk, ghostscript с api высокого уровня
- textract — оболочка для pdftotext
- pdfiijs — конвертер pdf в инвертированный индекс с использованием textiijs и poppler
- pdf2json — конвертер pdf в json на чистом js
Функциональные возможности многих модулей пересекаются, однако представляют
альтернативные API, и большинство из них требует установки внешних зависимостей
(таких как apt-get install poppler).
Вот несколько разных способов сравнивать модули:
pdf2jsonявляется единственным написанным на чистом JavaScript, что делает его самым простым в установке, особенно на маломощных устройствах, вроде одноплатного компьютера Raspberry Pi или на Windows, где внутренний код может быть не кроссплатформенным.- каждый из модулей вроде
mimeograph,hummusиpdf-extractобъединяют в себе несколько модулей низшего уровня для предоставления высокоуровневого API - множество модулей является надстройками для
pdftotext/poppler, консольных инструментов unix
Давайте сравним pdftotextjs и pdf-text-extract, они оба являются
обертками для pdftotext.
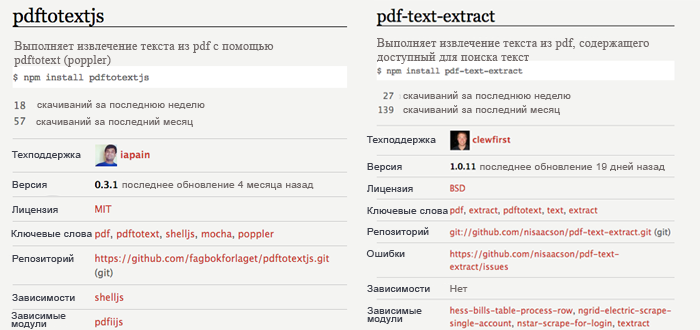
Оба модуля:
- были обновлены сравнительно недавно
- имеют собственные репозитории на github (это очень важно!)
- имеют описания
README - еженедельно устанавливаются некоторым количеством пользователей
- имеют свободную лицензию (кто-угодно может их использовать)
По package.json и статистике модуля трудно понять какой
из них лучше выбрать. Давайте сравним описания в README:

У обоих простые описания, указан статус сборки, есть инструкции по установке, понятные примеры и инструкции для проведения тестирования. Отлично! Однако какой же выбрать? Давайте сравним код:

pdftotextjs состоит из около 110 строчек кода, а pdf-text-extract — из 40,
однако, по сути, оба сводятся к следующей строчке:
var child = shell.exec('pdftotext ' + self.options.additional.join(' '));
Делает ли это один из них лучше другого? Трудно сказать. Важно, собственно,
вчитаться в код и сделать свой собственный вывод. Когда вы встречаете
удобные и полезные модули, используйте npm star modulename, чтобы оставить в
пакетном менеджере свой отзыв о модулях, которые вам понравились.
Организация процесса разработки с использованием модулей
npm отличается от большинства пакетных менеджеров тем, что устанавливает модули в папку внутри других существующих модулей. Предыдущее предложение может сейчас показаться бессмыслицей, однако это ключ к успеху npm.
Многие пакетные менеджеры устанавливают всё глобально. Например, если выполнить
команду apt-get install couchdb в Debian Linux, она попытается установить
последнюю стабильную версию CouchDB. Если вы хотите установить CouchDB как
зависимость для другой программы, и эта программа требует более раннюю версию
CouchDB, вам придётся деинсталлировать более новую версию CouchDB и затем
установить более старую. Установить обе версии нельзя, так как Debian умеет
устанавливать что-либо только в одном месте.
Так обстоят дела не только в Debian. Точно так же работает большинство пакетных менеджеров для различных языков программирования. Чтобы решить проблему с глобальной установкой зависимостей, описанную выше, было разработано виртуальное окружение, такое как virtualenv для Python и bundler для Ruby. Они разбивают ваше окружение на множество виртуальных, по одному на каждый проект, однако внутри виртуального окружения зависимости устанавливаются всё так же глобально. Виртуальные окружения не всегда решают проблему, иногда они её приумножают, добавляя новые уровни сложности.
При использовании пакетного менеджера Node.js устанавливать глобальные модули
крайне не рекомендуется. Точно так же, как в программах на JavaScript не
рекомендуется использовать глобальные переменные, так же и с установкой
глобальных модулей (разве что вам нужно чтобы модуль с загрузочным двоичным
кодом отображался в глобальном PATH, однако это требуется не всегда —
подробнее об этом позже).
Как работает require
Когда вы в Node.js вызываете require('some_module'), происходит следующее:
- Если в текущей папке есть файл с названием
some_module.js, Node.js его загрузит, в противном случае: - Node.js проверит текущую папку на наличие папки
node_modulesс папкойsome_moduleвнутри неё - Если он её не найдет, он поднимется на одну папку выше и повторит шаг 2
Этот цикл повторяется, пока Node.js не достигнет корневой папки файловой системы,
после чего он проверит наличие папок с глобальными модулями (например,
/usr/local/node_modules на Mac OS) и если some_module опять не будет найден,
он сгенерирует исключение.
Вот визуальный пример:

Когда текущей рабочей директорией является subsubfolder и происходит вызов
require('foo'), Node.js ищет папку с названием subsubsubfolder/node_modules. В
этом случае он её не найдет, так как папка по ошибке названа my_modules. Затем
Node.js поднимается на одну папку выше и повторяет попытку, то есть он ищет
subfolder_B/node_modules, которая также не существует. Третья попытка, тем не
менее, оказывается удачной, поскольку folder/node_modules существует и
содержит папку с названием foo внутри. Если бы foo в ней не было, Node
продолжил бы поиск вверх по дереву директорий.
Обратите внимание, что если бы Node.js был вызван в папке subfolder_B, он ни за
что бы не нашел subfolder_A/node_modules, так как он может увидеть
folder/node_modules только по пути вверх по дереву директорий.
Одним из преимуществ подхода пакетного менеджера Node.js является то, что модули
могут устанавливать зависимые модули конкретных рабочих версий. В данном случае
очень популярен модуль foo — он установлен трижды, по одному в папке каждого
родительского модуля. Причиной может быть то, что для каждого
модуля требуется другая версия foo, например для folder нужен
[email protected], для subfolder_A — [email protected] и т.д.
Вот что произойдет, если исправить ошибку в названии папки с my_modules на
более правильное node_modules:

Чтобы проверить, какой именно модуль будет загружен Node, можно использовать
команду require.resolve('some_module'), которая отобразит путь к модулю,
найденному Node.js в процессе прохода вверх по дереву директорий.
require.resolve может пригодиться для перепроверки того, что будет загружен
именно тот модуль, который вы ожидаете. Иногда оказывается, что существует ещё
одна версия того же модуля ближе к текущей рабочей директории, чем тот, который
вы хотели бы загрузить.
Как написать модуль
Теперь, когда вы знаете как искать модули и запрашивать их, можно приступить к написанию собственных модулей.
Наипростейший модуль из возможных
Модули Node.js исключительно мало весят. Вот один из наипростейших модулей:
package.json:
{
"name": "number-one",
"version": "1.0.0"
}
index.js:
module.exports = 1;
По умолчанию Node.js пытается загрузить module/index.js, когда вы запрашиваете
require('module'). Никакое другое имя работать не будет, если вы не пропишите
путь к нему в package.json в поле main.
Поместите оба файла в папку number-one (id в package.json должно
соответствовать названию папки), и вы получите работающий Node-модуль.
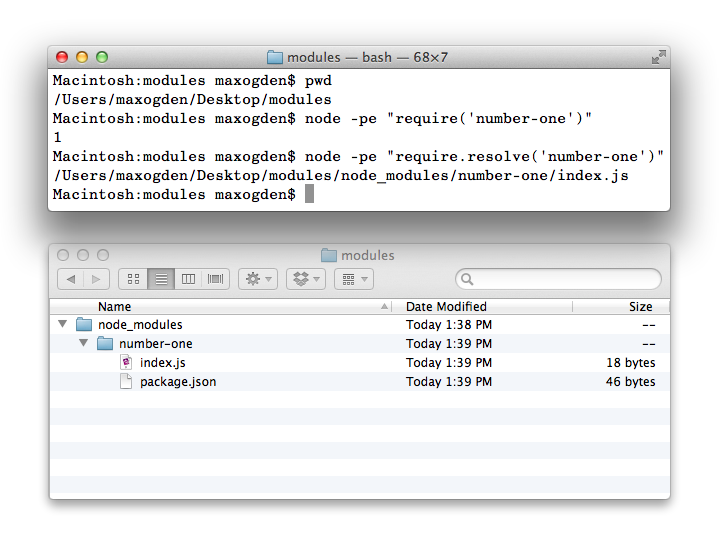
Вызов функции require('number-one') возвращает то значение, которое указано
для module.exports внутри модуля:
Еще быстрее создать модуль можно с помощью этих команд:
mkdir my_module
cd my_module
git init
git remote add git@github.com:yourusername/my_module.git
npm init
Выполнение npm init создаст валидный package.json и, если вы запустите его
в существующем репозитории git, он также автоматически добавит в
package.json поле repositories!
Добавление зависимостей
Модуль может содержать перечень каких-либо других модулей из npm
или GitHub в поле dependencies в package.json. Чтобы установить модуль
request как новую зависимость и автоматически добавить его в package.json,
выполните эту команду в корневой директории вашего модуля:
npm install --save request
Это установит копию request в ближайшую папку node_modules и сделает
package.json примерно таким:
{
"id": "number-one",
"version": "1.0.0",
"dependencies": {
"request": "~2.22.0"
}
}
По умолчанию, npm install установит последнюю официальную версию модуля.
Разработка на стороне клиента с использованием npm
Существует популярное заблуждение, что, поскольку в названии npm указано слово
«Node», он должен использоваться только для JS модулей на стороне сервера. Это
абсолютно не верно! Название пакетного менеджера Node.js подразумевает, что он
отвечает за управление модулями, которые Node.js упаковывает для вас в пакеты.
Модули сами по себе могут быть какими угодно — они всего лишь представляют из
себя папку с файлами, упакованную в архив .tar.gz, и файл package.json, в
котором указана версия модуля и перечень модулей, являющихся его зависимостями
(а также номера их версий, чтобы рабочие версии устанавливались автоматически).
Зависимости модулей являются обычными модулями, которые также могут иметь
зависимости — и так до бесконечности.
browserify — это утилита, написанная на Node, которая пытается переконвертировать любой Node-модуль так, чтобы он мог быть запущен в браузере. Не все модули удастся запустить таким образом (например, браузеры нельзя использовать для таких задач как хостинг HTTP-сервера), но многие модули действительно работают.
Чтобы попробовать npm в браузере, используйте RequireBin, приложение, созданное мной на основе Browserify-CDN, в основе которого лежит browserify, но для вывода используется HTTP (вместо командной строки, которая обычно используется для browserify).
Скопируйте этот код в RequireBin и нажмите кнопку предварительного просмотра:
var reverse = require('ascii-art-reverse');
// делает HTML консоль видимой
require('console-log').show(true);
var coolbear =
" ('-^-/') \n" +
" `o__o' ] \n" +
" (_Y_) _/ \n" +
" _..`--'-.`, \n" +
" (__)_,--(__) \n" +
" 7: ; 1 \n" +
" _/,`-.-' : \n" +
" (_,)-~~(_,) \n";
setInterval(function() { console.log(coolbear) }, 1000);
setTimeout(function() {
setInterval(function() { console.log(reverse(coolbear)) }, 1000);
}, 500);
Или взгляните на более сложный пример(не стесняйтесь поиграть с кодом, чтобы посмотреть что получается):
Выбираем инструменты правильно
Как любой хороший инструмент, Node.js лучше всего подходит для конкретного набора задач. Например, Rails, популярный веб-фреймворк, идеально подходит для сложной бизнес-логики, т.е. использования кода для представления реальных бизнес объектов, вроде счетов, ссуд и оборотного капитала. Хотя создание подобных вещей с помощью Node.js является технически возможным, без проблем не обойдётся, так как Node.js придуман для решения проблем ввода/вывода и не слишком подходит для использования в сфере «бизнес-логики». Каждый инструмент предназначен для решения своих задач. Надеюсь, это руководство поможет вам обрести интуитивное понимание сильных сторон Node.js и того, в каких случаях он может быть вам полезен.
Что не входит в компетенцию Node?
По большому счёту, Node.js — это всего лишь инструмент, используемый для управления операциями ввода/вывода в файловых системах и сетях, остальные навороченные функциональные возможности ложатся на посторонние модули. Вот некоторые вещи, выходящие за рамки компетенции Node:
Веб-фреймворки
Существует ряд веб-фреймворков, построенных на основе Node.js (под фреймворком следует понимать пакет программ, который пытается решить некую высокоуровневую задачу вроде моделирования бизнес-логики), однако Node.js веб-фреймворком не является. Веб-фреймворки, написанные на Node, не всегда разделяют его подход к наращиванию сложности, абстрактности и компромиссности, и могут иметь другие приоритеты.
Языковой синтаксис
Node.js использует JavaScript без каких-либо изменений. Феликс Гейзендорфер (Felix Geisendorfer) составил хорошее описание «стиля Node» здесь.
Языковые абстракции
При любой возможности Node.js использует самый простой из доступных способов выполнить задачу. Чем навороченнее ваш JavaScript, тем больше сложностей и компромиссов вам приходится использовать. Программирование — непростое занятие, особенно когда речь идёт о JS, у которого на каждую проблему по 1000 решений. Именно поэтому Node.js всегда пытается выбрать самое простое и универсальное из них. Если вы заняты задачей, для которой требуется сложное решение, и недовольны «простенькими вариантами», которые предлагает Node, вы можете без проблем решить её для своего приложения или модуля, используя любые абстракции на ваш вкус.
Прекрасным примером этому служит использование в Node.js колбеков. Изначально в Node.js проводились эксперименты с элементом под названием «промисы», которые предусматривали ряд приспособлений для того, чтобы асинхронный код выглядел более линейным. Они были изъяты из ядра Node.js по нескольким причинам:
- Их сложнее использовать, чем колбеки
- Их можно установить ввиде пакета из npm
Рассмотрим самое простое и базовое действие, которое производит Node: чтение файла. В процессе чтения файла вы хотите знать когда происходят ошибки, например, когда жесткий диск глохнет посередине процесса. Если бы промисы использовались в Node, дерево кода должно было бы выглядеть так:
fs.readFile('movie.mp4')
.then(function(data) {
// проведение действий с данными
})
.error(function(error) {
// обработка ошибки
});
Это всё усложняет, и не каждому такое понравится. Вместо двух отдельных функций Node.js использует один-единственный колбек. Он следует таким правилам:
- Если ошибка не произошла,
nullпередаётся в качестве первого аргумента - Когда происходит ошибка, она передаётся в качестве первого аргумента
- Остальными аргументами может быть что-угодно (обычно это данные или отклики, так как Node.js отвечает, в основном, за чтение или запись)
Отсюда стиль колбеков Node:
fs.readFile('movie.mp4', function(err, data) {
// обработка ошибки, выполнение действий с данными
});
Потоки исполнения/волокна/достижение параллельности без использования событий
Примечание: если эти названия ни о чём вам не говорят, возможно, вам будет проще освоить Node, так как избавление от знаний требует столько же усилий, сколько их получение.
Node.js использует потоки исполнения для ускорения процессов, но не отображает их пользователю. Если вы технически продвинутый пользователь, интересующийся почему Node.js был реализован именно таким образом, вам 100% следует почитать о структуре библиотеки libuv, I/O-слое C++, на котором построен Node.

Статья переведена благодаря спонсорской поддержке компании «Одноклассники».
